Как реализовать процесс непрерывного улучшения саморедактуры?
Публичный постДобрый вечер!
Я хочу узнать ваши идеи о том, как сделать процесс саморедактуры художественного произведения более эффективным.
Ниже описаны некоторые мои находки.
Заранее благодарен
Дмитрий Писаренко
Цель
Есть первый черновик романа, first shitty draft, как говорят наши западные партнеры. Это очень сырой черновик. Он не просто так называется shitty.
В рамках саморедактуры этот текст приводится в читабельный вид. В рамках саморедактуры устраняются все дефекты кроме грамматических ошибок, в том числе
- сухой язык,
- ненужные повторения,
- неуместный официоз, канцелярит, вычурно-цветастый язык ,
- анатомические невозможности,
- непреднамеренные логические нестыковки,
- кондовая экспозиция когда в первых нескольких главах нет никакого экшена, только описание биографии героя и места действия,
- описание того, что можно и нужно показать,
- длинноты,
- недостаточная эмоциональность,
- ненужные языковые сложности вроде деепричастных оборотов,
- недостаточно хорошо прописанные конфликты,
- грубые грамматические и стилистические ошибки,
- все то, что было лень делать во время написания первого черновика и
- все другие случаи, когда что текст плох.
Это такие ошибки, которые не исправят ни
- автоматические проверяльщики орфографии вроде aspell (мозгов нет),
- ни ChatGPT (мозги есть, но во-первых слишком зацензурены, во-вторых склонны делать ошибки начинающих авторов), ни
- редактор на белковой основе (потому что большинству вышеперечисленных вещей гораздо труднее научиться, чем орфографии).
Потому делегировать это нельзя.
Поэтому эти ошибки я исправляю сам, а мелочь вроде орфографии потом делегирую редактору.
Проблема
Все это идет очень медленно.
Первая попытка решения
Чтобы процессом управлять, нужно его измерять. Если бы на каждое маленькое дело, которое нужно сделать с текстом был бы тикет в Джире, то можно было бы считать количество тикетов по типам, можно было бы считать среднее время на исправление той или иной проблемы в тексте и т. п.
Но не буду же я заводить на каждую мелочь тикет в Джире? А почему не буду?
Ответ: Потому, что это слишком долго. Открыть страницу, потом вбить текст (включая контекст -- глава и место, где эта проблема есть). После исправления опять нужно открыть Джиру, найти нужный тикет и там мышкой отметить задачу как сделанную.
Здесь ряд проблем -- слишком много действий, это все очень долго и каждый раз, когда я покидаю текстовый редактор, я рискую отвлечься на что-то в браузере.
Если бы делать пункты действия можно было прямо в тексте, то все было бы иначе.
Вот так:
4-го июля 1945 года отцы основатели, Джон Уилкс Бут и Джессе Вентура отмечали годовщину высадки на Луну. Царила дружеская атмосфера.
# TODO 1: Что-то не так со временем.
# TODO 2: "Царила атмосфера" попахивает канцеляритом.
# TODO 3: "Джессе Вентура" или "Джесси Вентура"?
Все строки с решеткой (#) в начале -- это комментарии, они не попадут в конечный текст.
Это уже лучше, но есть проблема с нумерацией -- можно же замучаться вспоминать, какой номер был у крайней проблемы.
Это можно решить, если сделать небольшую программу, которая будет давать каждой проблеме уникальный идентфикатор. Назовем эту программу тудуп (TODO Processor).
На входе тудуп получает вот такой файл:
4-го июля 1945 года отцы основатели, Джон Уилкс Бут и Джессе Вентура отмечали годовщину высадки на Луну. Царила дружеская атмосфера.
# TODO: Что-то не так со временем.
# TODO: "Царила атмосфера" попахивает канцеляритом.
# TODO: "Джессе Вентура" или "Джесси Вентура"?
После работы тудупа файл превращается в вот такой:
4-го июля 1945 года отцы основатели, Джон Уилкс Бут и Джессе Вентура отмечали годовщину высадки на Луну. Царила дружеская атмосфера.
# TODO, ВЕСЕЛЫЙ-КАРЛСОН-25: Что-то не так со временем.
# TODO, ХИППУЮЩИЙ-ДОСТОЕВСКИЙ-35: "Царила атмосфера" попахивает канцеляритом.
# TODO, ЛИКУЮЩИЙ-ГОГОЛЬ-81: "Джессе Вентура" или "Джесси Вентура"?
ВЕСЕЛЫЙ-КАРЛСОН-25, ХИППУЮЩИЙ-ДОСТОЕВСКИЙ-35 и ЛИКУЮЩИЙ-ГОГОЛЬ-81 -- это идентификаторы каждой проблемы. Тудуп следит за тем, чтобы эти идентификаторы не повторялись.
Никто не мешает тудупу записать время добавления и время удаления той или иной проблемы. Здесь уже можно считать статистику -- интенсивность саморедактуры по времени (сумма всех добавлений и всех удалений проблем в ту или иную неделю).
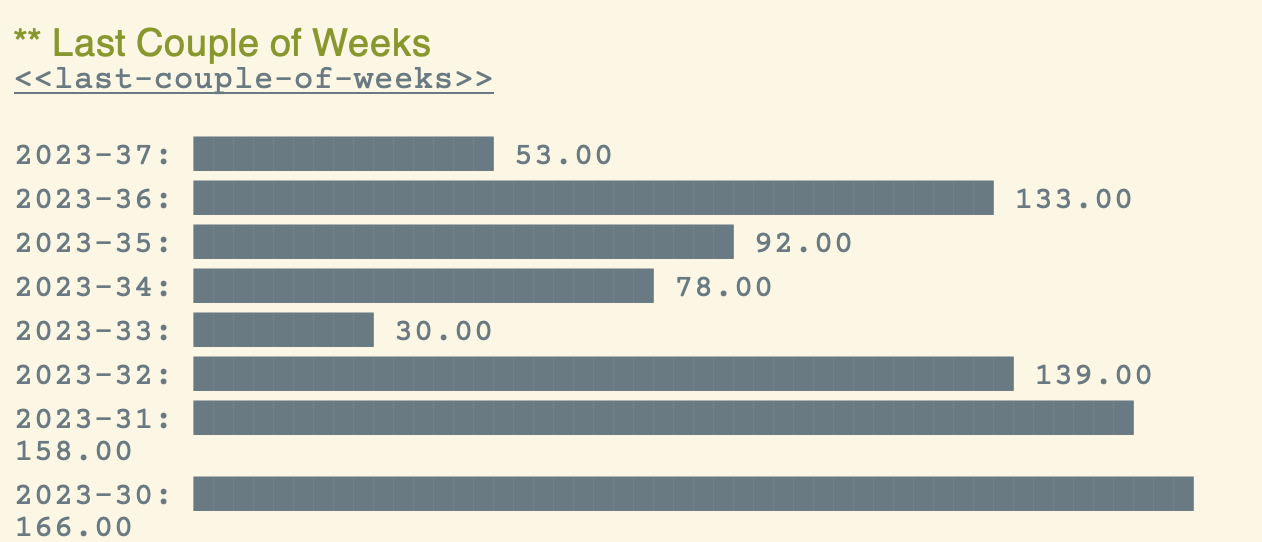
Можно посчитать средную интенсивность саморедактуры по дням недели.

Это все замечательно, но все еще не дает ответа на вопрос -- а как мне все-таки стать более эффективным?
Категории
Здесь мне пришла идея добавить категории пунктов действий.
4-го июля 1945 года отцы основатели, Джон Уилкс Бут и Джессе Вентура отмечали годовщину высадки на Луну. Царила дружеская атмосфера.
# TODO, ВЕСЕЛЫЙ-КАРЛСОН-25: Что-то не так со временем. #time
# TODO, ХИППУЮЩИЙ-ДОСТОЕВСКИЙ-35: "Царила атмосфера" попахивает канцеляритом. #ex
# TODO, ЛИКУЮЩИЙ-ГОГОЛЬ-81: "Джессе Вентура" или "Джесси Вентура"? #g
В конце текста каждого пункта действия появились категории, которые отмечаются решеткой:
#time: все, что связано со временем,#ex(expression): нужно подобрать лучшее выражение,#g(grammar): все, что связано с грамматикой, стилистикой, орфографией и т. п.
Это уже позволяет понимать наиболее частые категории.

Но этого тоже мало. Мы же не знаем, сколько времени в среднем уходит на работу по исправлению проблемы той или иной категории.
Мелкомасштабное отслеживание времени
Я добавил в редактор следующую функциональность: Если ввести в редакторе команду tt ses, то он пишет в особый файл, что сеанс саморедактуры открыт в такое-то время.
2023-09-12 12:01:08|/Users/my-novel/src/txt/ch006.org|SESSION START|# TODO, WONDERFUL-DUBINSKY-96: Describe ... #vcd
Когда я начинаю работать на тем или иным пунктом действия, то
- навожу курсор на соотв. строку (например,
# TODO, ВЕСЕЛЫЙ-КАРЛСОН-25: Что-то не так со временем. #time) и - ввожу в редакторе tt as.
В том файле появляется строчка:
2023-07-03 12:01:46|/Users/my-novel/src/txt/ch006.org|ACTION ITEM START|# TODO, ВЕСЕЛЫЙ-КАРЛСОН-25: Что-то не так со временем. #time
Когда я заканчиваю работу по тому или иному пункту действий, либо прекращаю сеанс саморедактуры, то это тоже фиксируется в этом файле.
Теперь можно считать более подробную статистику. Самый простой вариант -- трудозатраты по пунктам действия.
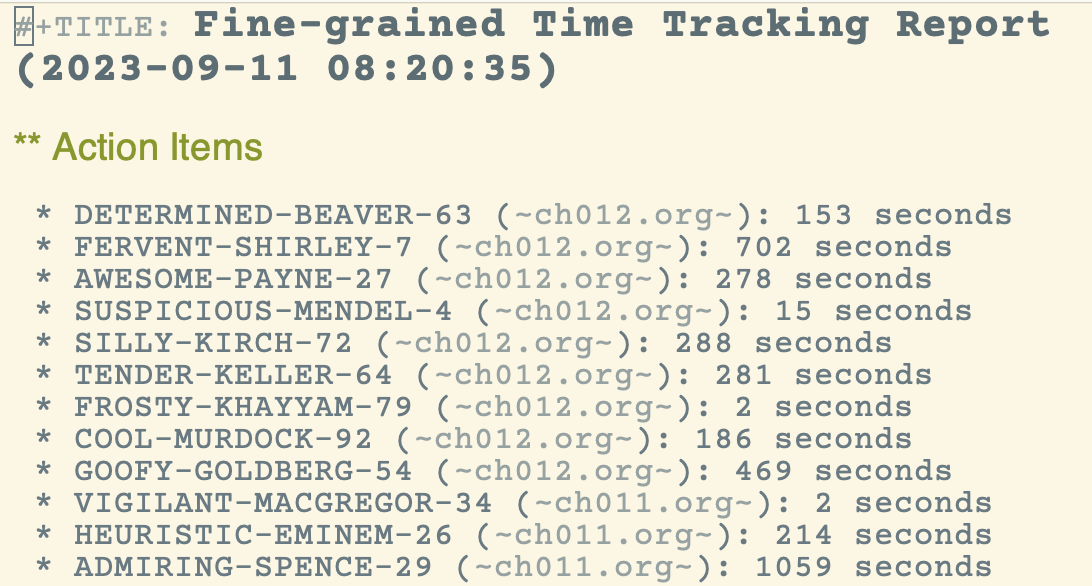
Можно считать среднее время по категориям.

Эту информацию можно использовать, чтобы понимать, какие виды работ (какие навыки саморедактуры) нужно улучшать в первую очередь.
Также можно посчитать время, для которого не определен пункт действия. Это время
- после начала сеанса и до начала работы над первым пунктом действия,
- между двумя пунктами действия и
- после завершения крайнего пункта действия и до завершения сеанса.
Сортивовка перечня дел
Со временем стало понятно, что некоторые виды работ обычно надо делать до других. Возьмем наш пример.
4-го июля 1945 года отцы основатели, Джон Уилкс Бут и Джессе Вентура отмечали годовщину высадки на Луну. Царила дружеская атмосфера.
# TODO, ВЕСЕЛЫЙ-КАРЛСОН-25: Что-то не так со временем. #time
# TODO, ХИППУЮЩИЙ-ДОСТОЕВСКИЙ-35: "Царила атмосфера" попахивает канцеляритом. #ex
# TODO, ЛИКУЮЩИЙ-ГОГОЛЬ-81: "Джессе Вентура" или "Джесси Вентура"? #g
Если мы перепишем Царила дружеская атмосфера., можем внести грамматические ошибки. Поэтому имеет смысл сначала делать большие изменения (переписывания кусков текста), а уже потом -- маленькие (вроде всяких грамматических мелочей).
Все это можно записать в отдельный файл и скормить тудупу.
{:action-items-sort-order [
:first "ps"
:then "baustelle"
:then "full-rewrite"
:then "fp"
:then "cleanup"
:then "plan"
:then "ns"
:then "b"
:then "s-is"
:then "s-5c"
Это значит:
- Сначала надо делать пункты действий категории
ps, - потом -- категории
baustelle, - потом --
full-rewriteи т. д.
Теперь тудуп может сам сформировать перечень действий -- файл, в котором сказано что и в какой последовательности надо делать.

Этот перечень дел, конечно, не идеален. Его назначение -- побудить меня начать делать хоть что-то, когда рациональный тип спит из-за отсутствия мыслетоплива.
Выученные уроки
Но от измерения и составления перечня дел непрерывное улучшение не возьмется.
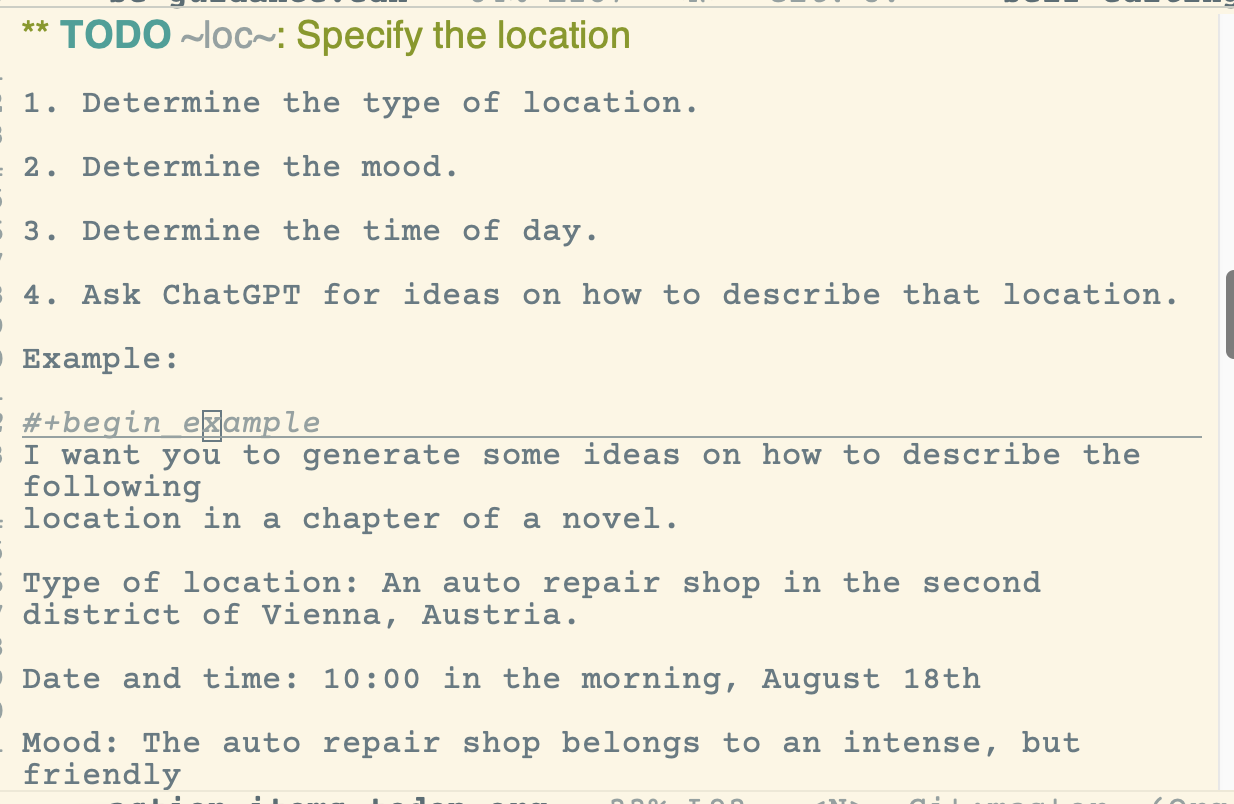
Если в рамках работы над пунктом действия той или иной категории я нашел что-то, что мне может пригодиться, то это надо где-то записать. Причем так, чтобы я вспомнил об этом "выученном уроке" (lesson learned), когда подобная ситуация (пункт действия той же категории) возникнет еще раз.
Для этого все материалы такого рода я фиксирую в файле вот так:
[:for-category "loc"
:add-this-hint [
"1. Determine the type of location."
""
"2. Determine the mood."
""
"3. Determine the time of day."
""
"4. Ask ChatGPT for ideas on how to describe that location."
""
...
Здесь записано нечто, что однажды помогло мне выполнить пункт действия категории loc.
В автоматическом перечне дел этот текст выводится перед всеми пунктами действия этой категории.
Неудачный опыт с process mining
Есть такое ПО, которое берет событийный след того или иного процесса и выдает блок-схему (BPMN), которая описывает этот процесс.
Я попытался это сделать с данными о саморедактуре, но получившаяся диаграмма полезных знаний почти не дала.
Выявление усталости
Еще была идея выявлять, когда я плохо работаю из-за усталости.
Сначала я думал про высокотехнологичное решение -- сделать ПО для распознавания зевков или воспользоваться готовой камерой, которая это умеет.
В итоге ограничился низкотехнологическим решением: В одном из файлов стал фиксировать зевки.
В итоге заметил, что они начинаются около 07:30. Отсюда закономерный вывод -- примерно в это время выпить кофе и таким образом компенсировать усталость.
Режимы управления психикой
Глядя на эти замеры пришла мысль о том, что есть три режима управления психикой:
- Линейный
- Нелинейный
- Неопределенный
Линейный режим -- это когда есть четкая последовательность шагов и нужно выполнить их максимально быстро и точно. Это понятные в целом дела.
Линейный этот режим потому, что чем больше времени и внимание уделяется этому делу, тем быстрее оно будет сделано (время, помноженное на мыслетопливо обратно пропорционально трудозатратам).
Если во время делания линейных дел пойти погулять, то от этого будет только торможение (дело сделается позже).
Пример линейного процесса из ИТ: Устранение тривиальных багов:
- Взять логи.
- Найти место с ошибкой (стек-трейс).
- Дальше несколько вариантов:
3.1. Сказать эксплуантам, что код правильный, а это у них руки кривые (неправильная конфигурация, или так попросили сделать).
3.2. Исправить ошибку.
Пример линейных процессов в саморедактуре:
Спросить ChatGPT, нет ли ошибок с грамматикой (разбить весь текст главы, скормить ИИ и потом понаделать пунктов действий для ошибок).
Сокращение текста (удаление слов из предложений, без которых и так все понятно).
Нелинейный режим управления психикой -- это когда на производительность нельзя повлиять напрямую.
Примеры таких процессов из других областей:
Природа преобразует семена в колосья, но фермер не может напрямую управлять этим процессом. Может управлять только опосредованно -- через удобрения, полив, пропалывание сорняков и т. п.
Также невозможно напрямую управлять беременностью.
Применительно к саморедактуре полезна метафора Выготского:
Облака мыслей, гонимые ветрами мотивов, проливаются дождём слов.
Ключевой момент: Вся эта погода происходит автоматически. Напрямую на этот процесс повлиять нельзя.
Но можно
- повлиять на облака мыслей (скормить психике материалы, могут ее побудить что-то сделать),
- усилить ветра мотивов (накрутить себя и вспомнить, ради чего стольким пожертвовано) и
- поставить ведерко, чтобы не потерять ни одной капли дождя слов (т. е. всегда иметь при себе блокнот и пользоваться редактором, в котором легко фиксировать эти дожди слов, в т. ч. по кусочкам).
В таком режиме психика работает, когда надо сделать что-то более-менее творческое, где нет однозначных ответов.
Примеры нелинейных процессов в саморедактуре:
Создание образов. Заменить "Вошла очень красивая женщина" на нечто такое, где красота не будет упомянута, но читатель сам все поймет. Пример: Метод 25. Это когда нужно записать 25 вариантов решения той или иной задачи (например, 25 вариантов показать, что женщина очень красивая так, чтобы это было оригинально). Первые варианты будут штампами. Чем ближе к 25-му варианту, тем выше вероятность придумать что-то оригинальное.
Преобразование скучных сцен в менее скучные. Было: "Герой выпил кофе." Стало: "Герой выпил кофе, черный как душа узкоконечника."
Создание сцен. Сцена -- это единица истории, в которой есть 4 обязательных (запускающее событие, усиливающиеся сложности, кризис, кульминация) и один опциональный (развязка) элементов. Кажется, что поданная в таком формате информация лучше усваивается психикой читателя, потому что мозги так устроены.
Все ситуации, когда видно, что текст плох и нет явных идей, как его улучшить.
Когда психика ходит туда, не знаю куда в поисках того, не знаю, чего, могут помочь всякие "удобрения" вроде прогулок, рассматривания котиков и других непродуктивных вещей. В особо тяжелых случаях мне помогала пешая прогулка на 8-10 километров. Это двигает большинство задач с мертвой точки.
Трудозатраты на выполнение нелинейных задач не связаны напрямую с временем и мыслетопливом.
По идее, чем большая часть работы проходит в линейном режиме, тем эффективнее она идет. Чем большую часть работы можно формализовать в виде блок-схем, тем меньше надо думать.
С другой стороны природный способ мышления, про который говорил Выготский, тоже нужно изучать. Облака и ветра -- это замечательно, но предполагаю, что в психике есть еще много разных элементов (огнедышащие драконы, штучки, связанные с сексуальностью), которые, наверное, можно использовать для повышения производительности.
Дмитрий, подскажите, пожалуйста, а как выглядит процесс получения "first shitty draft"? То есть у вас есть какой-то план сюжета или Вы просто пишите пока есть вдохновение?
В списке проблем, мне как человеку далекому от творчества соседства "непреднамеренные логические нестыковки" и "описание того, что можно и нужно показать" несколько смущает?
Возможно, если Вы будите редактировать не все произведение в конце, а работать по главам это ускорит Вас...
Выявление усталости
Можно пользоваться Welltory