

Ситуация такая – есть большая ИТ компания (как обычно, вымышленная), предоставляющая свои услуги всем людям. Пусть это будет социальная сеть, которой пользуются десятки миллионов человек. С инженерной точки зрения – это несколько дата-центров по всей стране в каждом одновременно находится несколько сотен серверов компании. В дата-центрах работают инженеры. Иногда системные администраторы, работающие в центральном офисе, называют их удлинителями рук, так как им поручают не самую квалифицированную работу (с точки зрения системных администраторов): включить/выключить сервер, заменить в сервере неработающий компонент, устранить какой-то типовой сбой.
В этой компании системный администратор – это высококвалифицированный специалист, а не «эникейщик», как в большинстве компаний. А вот инженер в дата-центре считается менее квалифицированной позицией.
Диаграмма к этому примеру находится по этой ссылке.
В этой вымышленной ситуации мы много лет назад разбирали следующую проблему. Инженеры в дата-центрах, считали администраторов в центральном офисе м%даками, потому что они не давали им прав супер-пользователей. Из-за этого инженеры очень долго решали некоторые проблемы, так как для их решения требовалось выполнять какие-то команды с правами супер-пользователя. Но у инженеров прав нет, соответственно, надо было бегать за администраторами и просить их. А они заняты, по встречам ходят, с архитекторами что-то там постоянно обсуждают. А достучишься ты до администратора, он выполнит команду… А теперь надо буквально кое-что с сервером ещё сделать и выполнить эту команду еще раз, только администратор опять не доступен – сиди и жди его. Когда полчаса, когда два часа, а когда только на следующий день. Так и растягивается решение простой задачи чуть ли не на неделю, а были бы у инженеров права супер-пользователей, то за пару часов бы справлялись.
Конечно, и администраторы считали инженеров м%даками, при этом не самыми образованными. Если им дать права супер-пользователей (на минуточку!!!) на продуктивные сервера, да они там такого могут наворотить! Мало того, прецеденты были, когда одно неосторожное движение инженера привело к простою сегмента серверов на полдня. Ох и влетело же потом администраторам от руководства…
И конечно же с мантрой «никто не м%дак» мы приступили к распутыванию этого клубка при помощи диаграммы разрешения конфликтов.
— Итак, значит права супер-пользователей нужны инженерам, чтобы быстрее устранять сбои. Но одновременно с этим мы не даём инженерам права супер-пользователей, чтобы они сами реже ломали систему. Похоже?
— Да, похоже.
— Давайте теперь найдем общую цель, для которой нам одновременно надо и чтобы инженеры быстрее устраняли сбои, и чтобы они реже сами чего-то ломали.
— Нам это нужно, чтобы снизить простои серверов. Годится такая цель?
— Боюсь, что это лихо спрятанная за синонимами тавтология. Я же правильно понимаю, что сбой в данном случае – это синоним простоя?
— Да, правильно.
— То есть, вам нужно быстрее устранять сбой, чтобы снизить время нахождения сервера в состоянии сбоя?
— Ну как-то так, да.
— Звучит как будто надо сбросить вес, чтобы похудеть или найти работу, чтобы не быть безработным. Зачем вам нужно снижать время простоя серверов?
— Мы стараемся оказывать нашим пользователям самый лучший сервис, чтобы качество наших услуг было на высоте, пользователи были довольны и…
— Чтобы не лишили премии?
— Чтобы не лишили премии, да.
— Хорошо! Общих целей может быть много и это прекрасно. В итоге получается ситуация, когда инженеры хотят добиться общей цели и администраторы хотят добиться общей цели, но… друг друга считают м%даками. Это же неправильно?
— Конечно неправильно, а что делать?
— Как раз для решения таких конфликтов Элияху Голдратт и предлагал использовать свою диаграмму разрешения конфликтов. Мы строим с вами эту диаграмму. Это будет четыре улитки и одно противоречие. Дальше мы проводим гигиену улитками и смотрим, какая из них может развалиться. Давайте сейчас для простоты во главу поставим общую цель с премией, тогда мы получим следующий каркас диаграммы:
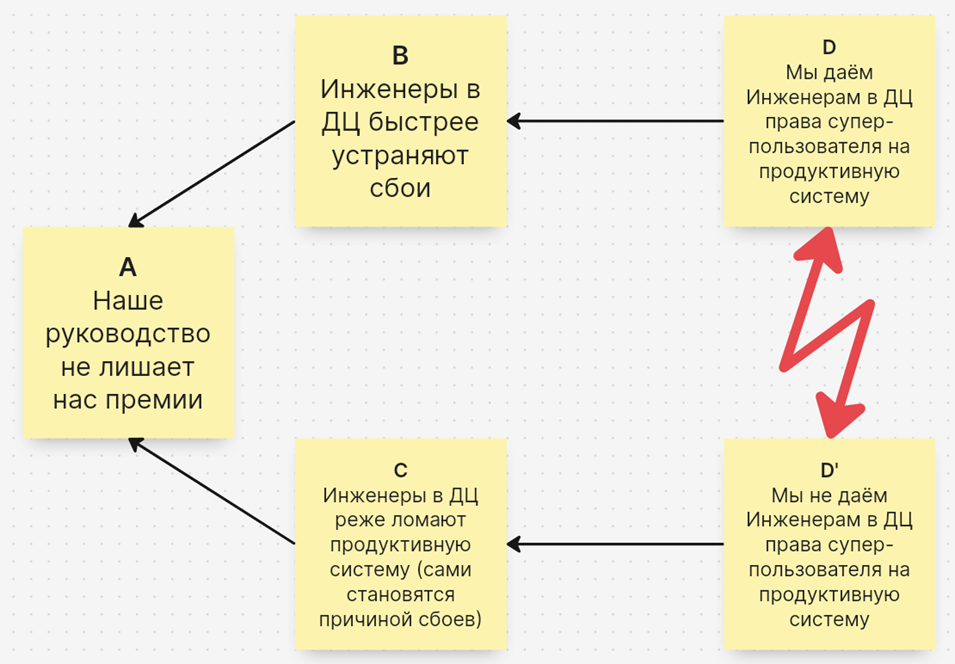
— Похоже на правду?
— Да, очень похоже. Давай это анализировать.
— Поехали. Начнем со связи B-D. Коллеги-инженеры, почему вы считаете, что если вам дадут права супер-пользователей, то вы будете быстрее устранять проблемы пользователей?
—Потому что нам не надо будет ловить администраторов и просить их выполнять команды. Вы не представляете, как бывает трудно поймать кого-то из них на своем рабочем месте. А если для устранения проблемы требуется несколько итераций «сделать-проверить», а каждая проверка идет только через администратора, то тут реально мы можем неделю ковыряться с задачей, на которую требуется пара часов.
— Ну что, коллеги-администраторы – всё так, да?
— Да. Мы в офисе постоянно заняты планированием новых разработок. Нас команды зовут для консультаций, и архитекторы советуются, как мы будем проектировать какую-то новую фичу. Мы действительно не всегда можем мгновенно отвечать.
— А если бы вы могли бы мгновенно отвечать, то проблема бы исчезла?
— Наверное да, но как?
— Дежурного администратора, например, завести. Кто-то, кто каждый день на связи и помогает инженерам.
— Как идею мы бы это зафиксировали, но я на этапе реализации вижу много сложностей. Как минимум из-за того, что у каждого из нас своя область ответственности. И, скажем, если речь идет о серверах, раздающих картинки, то с этим надо идти к Олегу, а если сервера, обслуживающие сообщения, то к Андрею. Даже если сбой один и тот же и команду нужно выполнить одну и ту же, то я не готов сказать, что это будет хорошей идеей, когда кто-то из нас будет что-то делать в той области, где не он хозяин.
— С другой стороны это создаст причины для выращивания внутри вас кросс-функциональности.
— Согласен. Поэтому, давайте зафиксируем эту идею и посмотрим, какие ещё у нас есть варианты.
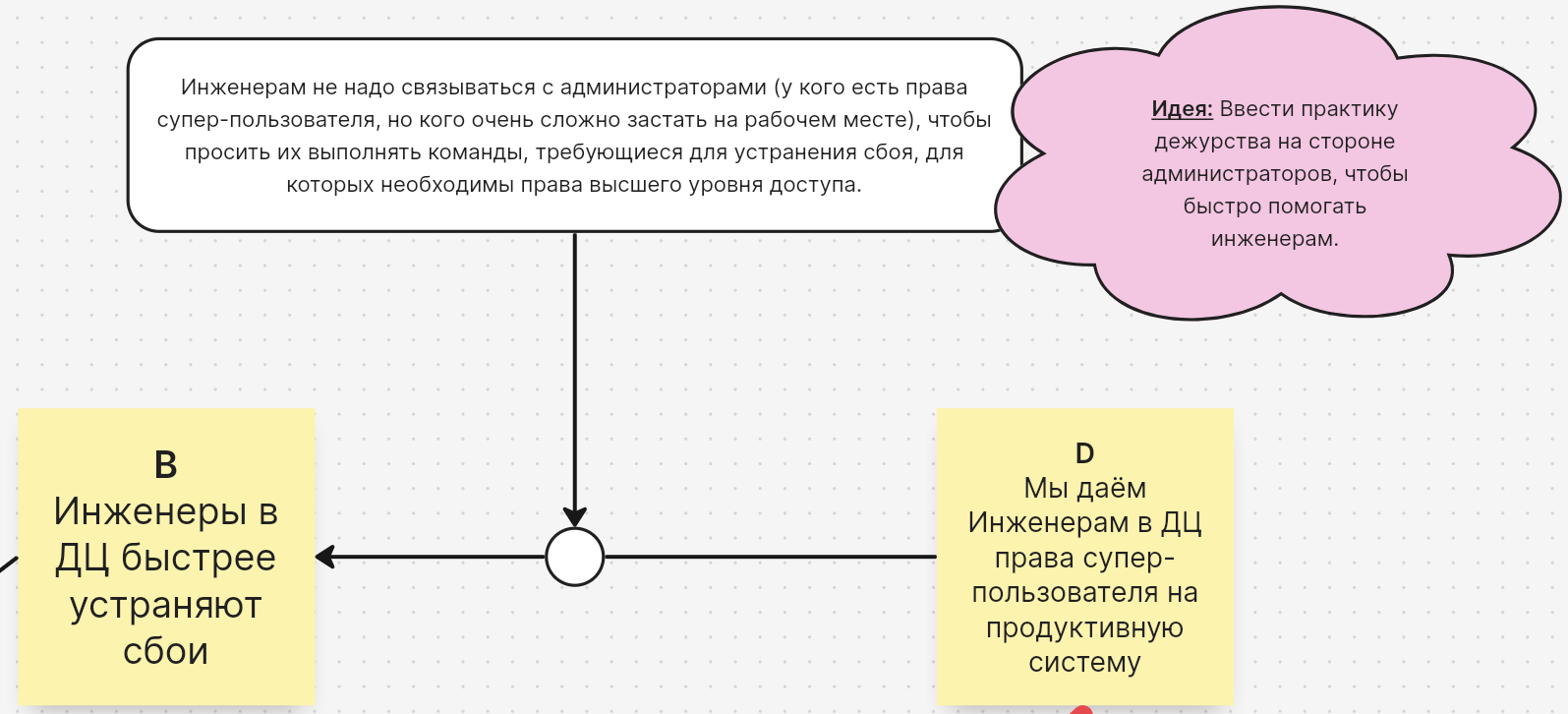
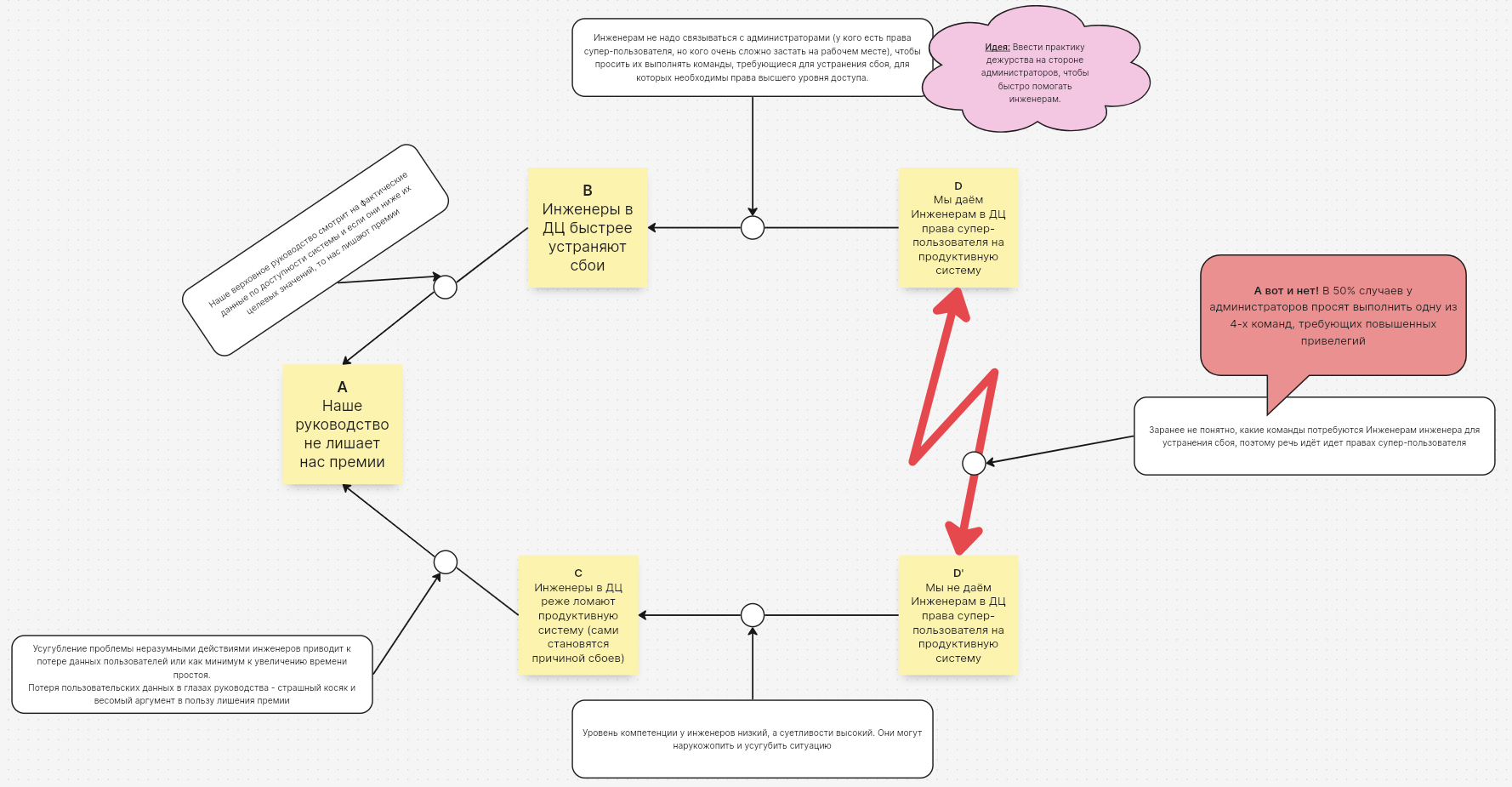
— Давайте посмотрим связь A-B. Почему вы думаете, что если инженеры будут быстрее устранять сбои, то руководство не лишит вас премии?
— Вообще это у нас в процедуре расчёта премии написано.
— Прямо так и написано? «Если инженеры в ДЦ будут …»
— Нет, конечно. Там написано про доступность сервиса, регламентировано максимально-возможное время простоя или деградации, ну то есть, когда сервис работает, но либо не полностью, либо тормозит.
— То есть, если на каком-то сервере произошел сбой, то пока этот сервер не починить, вам идет время простоя. Так?
— Не совсем. В особо критичных направлениях у нас сервера резервируются. То есть, если один сломался, то там их еще десять и они выключают этот сломанный из игры и сами справляются, а мы неспешно этот сервер можем чинить. Плохо, когда сбой происходит в том месте, где нет резерва или резерв подключается не автоматически, а вручную. Вот там-то чем быстрее починишь, тем меньше простоя.
— А почему вы тогда там не сделали резервирования?
— Там это не столь критично, плюс очень много уникальностей. У каждого сервиса какие-то свои настройки, и этих сервисов два десятка. Если каждый из них дублировать, то мы раздуем парк серверов. И если учесть, что бюджет у нас не резиновый, то для резервирования второстепенных сервисов нам придется тратить сервера, которые могли бы поставить на основное направление.
— А сервера у этих сервисов совсем-совсем разные? Можно ли делать какие-то полуфабрикаты? То есть, выделить какую-то общую для всех часть настроек и потом при необходимости превращать этот сервер в необходимый?
— Ну такое себе, если честно. В какой-то момент появится точка принятия решения: нам чинить этот сервер или готовить ему замену… А тут инженер сам наверняка не сообразит…
— Понятно, и опять будет искать администратора, чтобы задать ему вопросы.
— Именно. Мы думаем над этими вещами, в частности, вот эти менее критичные сервисы передать в сторонние облака, но это отдельная тема. Давайте посмотрим, чему еще нас может научить эта диаграмма.
— Хорошо. Давайте посмотрим связь А-С. Почему руководство не лишит вас премии, если инженеры будут реже ломать продуктивную систему?
— Тут опять же вопрос о доступности. Просто, одно дело, когда происходит сбой, а совсем другое, когда кто-то неопытный начинает неаккуратно работать с системой изнутри. Был у нас такой Эдвард-руки-UPDATE-без-WHERE … Внес изменение на одном сервере, думал, что изолировано что-то тестирует, а изменение тут же по всей сети реплицировалось. Получилось, что всем клиентам подарили месяц бесплатной подписки. А могли бы и отнять. Или удалить. Страшная вещь… Тогда мы еще маленькие были, плюс пиар-служба помогла это обыграть как подарок на наш день рождения.
— Как я понимаю, тут не столько последствия, сколько сам факт такого сбоя является ужасным косяком.
— Хуже, даже само существование такого риска… Особенно после случая, когда мы новым обновлением сломали механизм обновлений… Ну и сервера положили… Все это 4 апреля, праздник 404 чтоб его…
— Да, понимаю. Давайте посмотрим связь C-D’: почему, если вы не будете давать инженерам права супер-пользователей, то они будут реже ломать систему?
— Давайте смотреть правде в глаза, кто такой инженер в дата-центре? Это студент, вчерашний школьник. Он научился собирать компьютер и считает себя специалистом. Плюс мы его взяли в компанию, и он теперь понимает, что раз он работает в таком месте, то он точно профессионал! Молочный мозг еще не выпал, а суетой и нервозностью менеджеры его уже заразили. Опыта мало, знаний не много, страха никакого, а быстрее разобраться с проблемой хочется. Страшная смесь…
В этом месте мне показалось, что я нащупал ключ к разрешению проблемы – развитие. Займитесь развитием ваших инженеров и вам будет не страшно им доверять.
— А почему бы вам не заняться обучением и развитием ваших сотрудников, чтобы они не были столь опасны?
— А кто сказал, что мы эти не занимаемся? Мы инженеров развиваем активно, обучаем их много и многому?
— Почему же тогда у них уровень компетенции низкий?
— А на этот вопрос у меня есть ответ! Как только инженер набирается навыков и опыта, он перестает быть инженером и переходит на позицию администратора, а то и вовсе уходит в команду к разработчикам. А на его место приходит новый. Такой же, каким тот был изначально.
— Ага, понятно. Обучая инженеров, вы решаете вопрос нехватки администраторов и разработчиков, а не вопрос низкой квалификации инженеров.
— Именно!
— Что ж, а я надеялся, что здесь мы увидим решение.
— Увы. Но в итоге что получается, мы прошли всю диаграмму и у нас только одна идея?
— Мы прошли еще не всю диаграмму. У нас остался конфликт D-D’. По какой-то причине эти два решения находятся в конфликте.
— Ну это же очевидно, мы не можем одновременно и дать, и не давать права.
— Тут смысл не в том, почему нельзя выполнять это одновременно главный вопрос: а почему они в конфликте? Почему мы думаем над правами супер-пользователей?
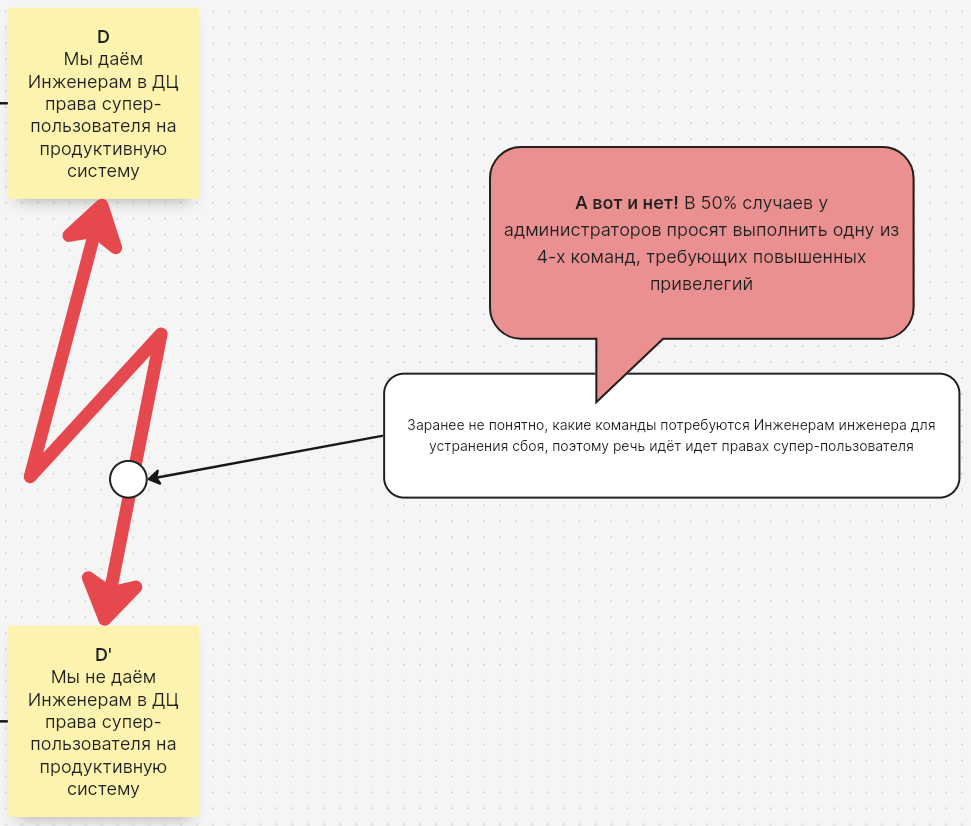
— Потому что мы заранее не знаем, какие команды инженерам потребуются среди всего того множества команд, требующих повышенных привилегий.
— А сколько всего есть команд, которые требуют супер-пользователя?
— Да тысячи!
— А если вспомнить десяток последних вопросов от инженеров, то это же будут все разные команды?...
звуки сверчков
— Вообще… Что-то мне подсказывает, что минимум в половине случаев это одна из трех, может быть, четырех команд.
И тут у команды администраторов запускается мыслительный процесс:
— Точно! Слушай, я же могу создать для них страничку, доступную только в локальной сети дата-центра и сделать там 4 кнопки на каждую из этих команд. И в принципе, мы можем как минимум ускорить работу в половине случаев.
Дальше пошло обсуждение деталей реализации, мало того, уже за 20 минут появился первый прототип этой странички и ребята радостно его протестировали на одном из тестовых серверов.
Эта история стала очередным примером, подтверждающим фразу, которую я услышал от Елены Федурко: «Конфликт часто возникает, когда мы какое-то решение считаем необходимым, а в реальности оно достаточное».
Выдать супер-пользователя всем – достаточно. Но достаточно с избытком. Можно было обойтись и менее радикальными методами.
Ох... больная и близкая тема - последние 7 лет именно этим вопросом и занимаюсь.
Как очень простой пример для демонстрации методики - хорошо.
Но реально применять общий подход мышления к сфере где есть целая индустрия решению любых проблем в этой области - к выводам в целом корректным, но очень обобщенным.
В данном случае, на самом деле конфликт совсем не в этом - это классический конфликт между развитием и поддержкой.
Поддержка или эксплуатация - как финальный и на самом деле самый важный ( точнее единственный этап, когда идет польза) почти всегда не учитывается на этапах проектирования и разработки - у Максима был офигеннейший доклад про жизнь после релиза.
И вопрос тут не в разных квалификациях - а в очень кривом видении мира - так называемых системных администраторов. Так сложилось в конкретной организации видимо - хотя как раз так бывает редко - истинные сисадмины в первую очередь думают о том, что не будет работать во время эксплуатации и как это можно чинить.
То есть, вкратце: если у вас разнесена ответственность за развитие и эксплуатацию - команда эксплуатации должна иметь все необходимые инструменты, информацию и компетенции (крайне желательно оптимальные по стоимости) для обеспечения требуемых параметров сервиса ( например RTO, RPO, качество данных, гибкость - время и усилия перенастройки и т.п.) К чему и пришли - что надо бы им сделать инструменты - а вообще-то надо сразу решать какого уровня компетенциями должны обладать члены команды, какие им нужны инструменты и знания (знания в примере все равно остались спрятанными в головах конкретных сисадминов) , чтобы укладываться в заданные параметры качества - это точно такая же часть системы, как и код, как и СУБД и сервера.
А тут мы видим ,что люди которые занимаются проектированием - об этом совсем не думают, при этом еще и свою компетенцию и знания инкапсулируют в себе.
И даже влияние времени простоя на их зарплату видимо не помогает - хотя это очень странно.
Очень печальная картина - хотя и повсеместная.
По мне, так изначальная проблема и не выявлена и не решена - она к сожалению в не инженерном подходе к проектированию и реализации
:(
Но если методика грозовой тучи хотя бы подвинула недосисадминов к этому - то уже хорошо.
Ну либо это очень прощенный пример :)
в слове "решаетЕ" потерялась одна "е"