Пока мы общались с чат ботами, пропустили публикацию самого большого открытый датасет из JIRA.
Вкратце,
select count(distinct project_id), count(*) from Issue;
39 458232
Немного базовой статистики.
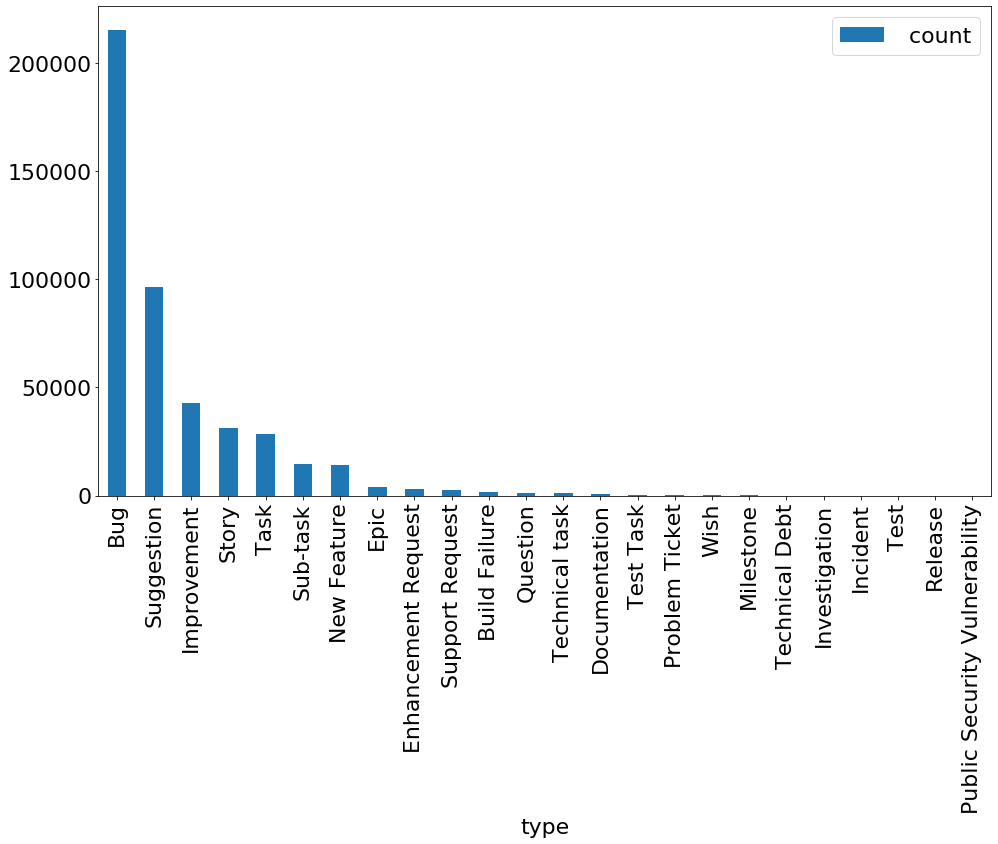
- Проектах в основном состоят из багов
select type, count(*) c from Issue
group by type order by c desc
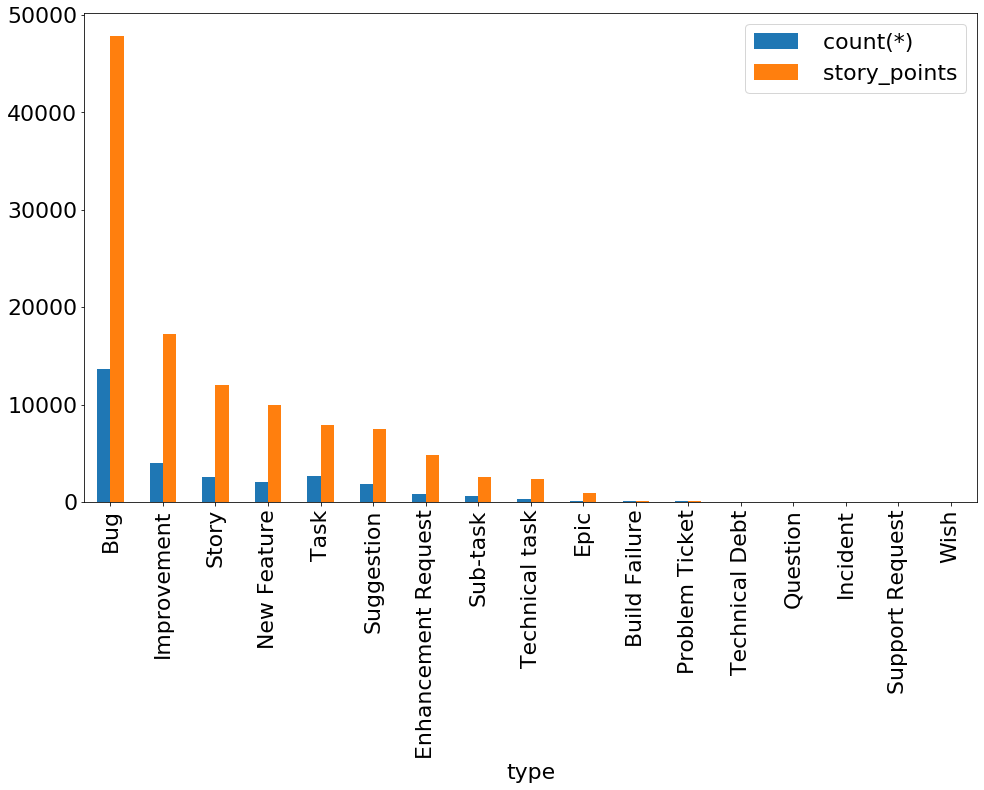
- Закрывают в основном баги не только с штуках но и в стори поинтах
select type, count(*), sum(story_point) c from Issue
where status ='Closed' and story_point between 0 and 100
group by type order by c desc
- Фантазия статусов Resolution, когда надо закрыть тикет без фикса, впечатляет
select resolution, count(*) from Issue
where status = 'Closed'
group by resolution;
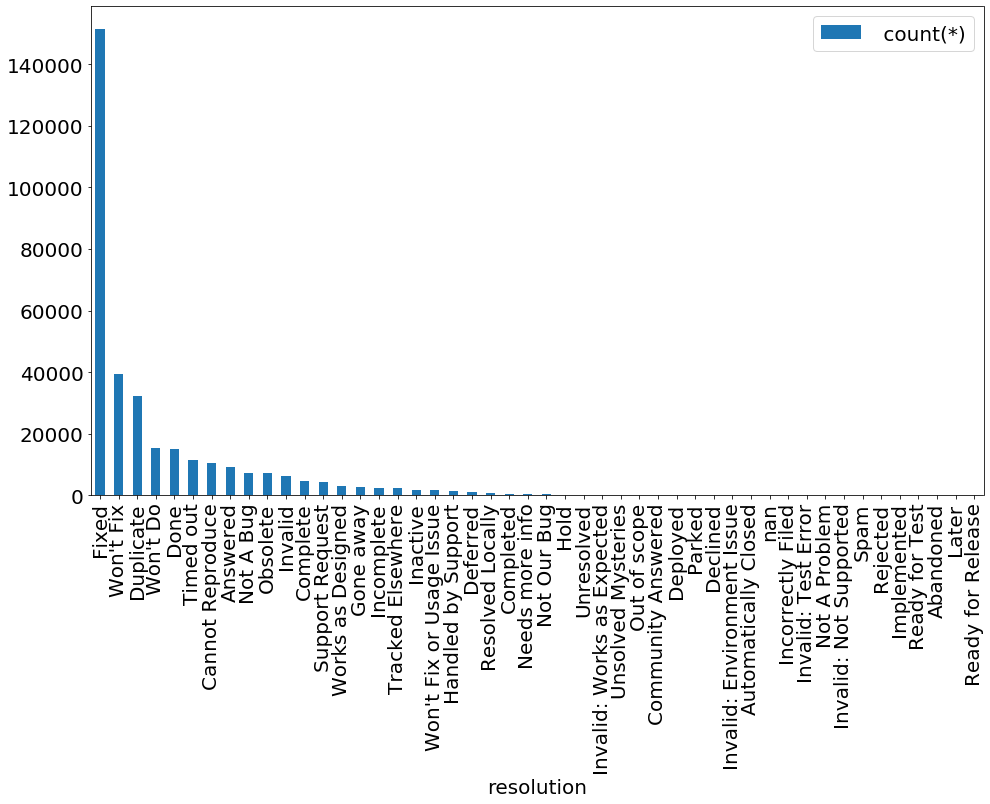
Кстати, вероятность то, что по закрытой JIRA был сделан фикс - примерно 55%.
Что это может сказать относительно планирования, обезьян и прочего? На воркшопах и больших роадмапах мы рисуем и планируем прекрасные фичи, которые будут сделаны, а потом возвращаемся на рабочие места и, в основном, фиксим неказистые незапланированные баги.
P.S. Мне кажется, крайне интересный датасет, где можно проверить десятки и сотни гипотез.
P.P.S. ML модель, которая оценивают стори поинты, тоже уже опубликована